
А если посчитать всё сразу, то получится, что DeepSeek вложил в обучение модели вполне сравнимо с вложениями фейсбук в LLama. Llama. At the time, many assumed that the open-supply ecosystem would flourish provided that corporations like Meta - big companies with large data centers filled with specialized chips - continued to open source their technologies. Companies just like the Silicon Valley chipmaker Nvidia initially designed these chips to render graphics for computer video video games. You need to use π to do helpful calculations, like determining the circumference of a circle. You can too use DeepSeek-R1-Distill models utilizing Amazon Bedrock Custom Model Import and Amazon EC2 cases with AWS Trainum and Inferentia chips. With AWS, you can use DeepSeek-R1 models to build, experiment, and responsibly scale your generative AI ideas by using this powerful, price-environment friendly model with minimal infrastructure funding. These require more computing power when people and businesses use them. Updated on 1st February - After importing the distilled model, you can use the Bedrock playground for understanding distilled model responses for your inputs. The mixture of consultants, being similar to the gaussian mixture model, can be educated by the expectation-maximization algorithm, similar to gaussian mixture fashions. Designed for top efficiency, DeepSeek-V3 can handle massive-scale operations without compromising velocity or accuracy.
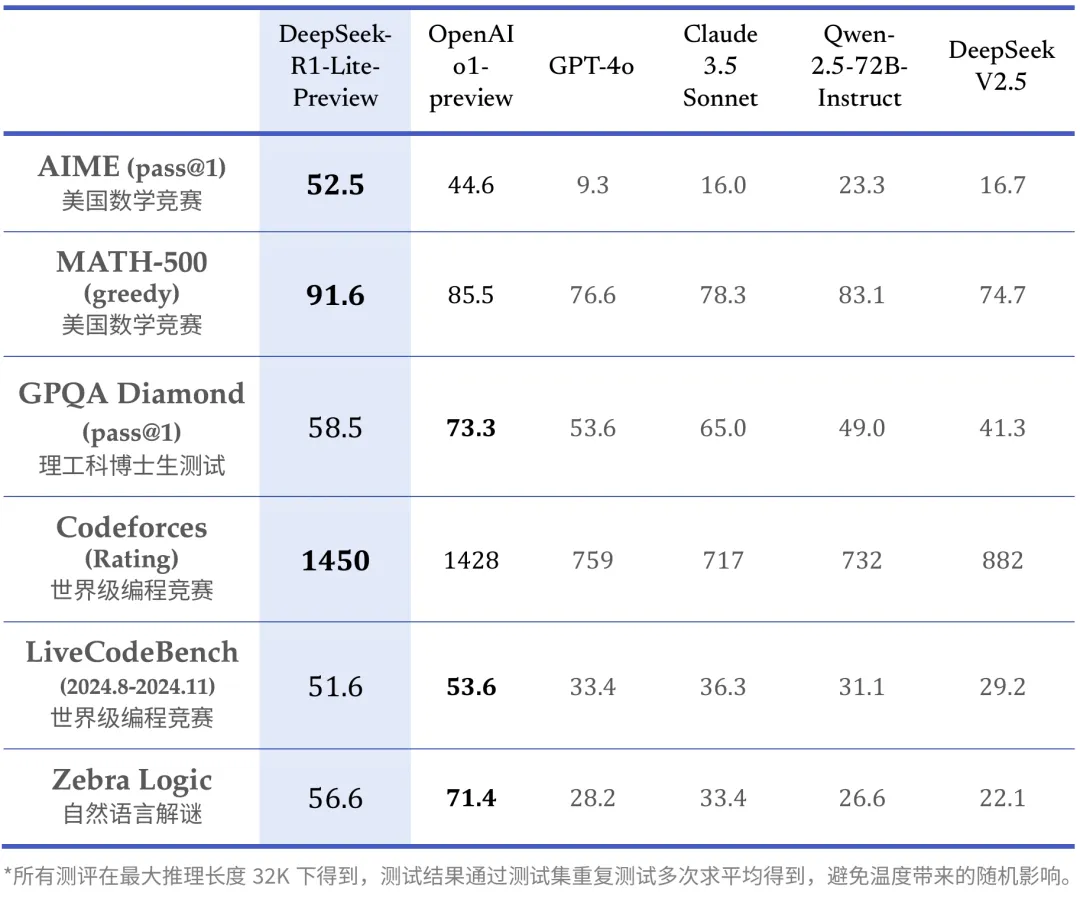 To deal with these points and further improve reasoning performance, we introduce DeepSeek-R1, which incorporates chilly-begin information before RL. DeepSeek is making headlines for its efficiency, which matches and even surpasses prime AI fashions. On high of the efficient architecture of DeepSeek-V2, we pioneer an auxiliary-loss-Free DeepSeek Chat technique for load balancing, which minimizes the performance degradation that arises from encouraging load balancing. Persons are very hungry for higher price efficiency. Longer Reasoning, Better Performance. The extra efficiency comes at the cost of slower and dearer output. That mixture of performance and decrease value helped DeepSeek's AI assistant turn into probably the most-downloaded free app on Apple's App Store when it was released within the US. On Jan. 10, it released its first free chatbot app, which was based mostly on a brand new model referred to as DeepSeek-V3. It is reportedly as highly effective as OpenAI's o1 mannequin - released at the tip of last yr - in duties together with mathematics and coding. Additionally, DeepSeek-V2.5 has seen vital enhancements in tasks similar to writing and instruction-following. DeepSeek-R1-Lite-Preview reveals regular score enhancements on AIME as thought length increases. This extends the context length from 4K to 16K. This produced the bottom models. At an economical cost of solely 2.664M H800 GPU hours, we full the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the at present strongest open-supply base model.
To deal with these points and further improve reasoning performance, we introduce DeepSeek-R1, which incorporates chilly-begin information before RL. DeepSeek is making headlines for its efficiency, which matches and even surpasses prime AI fashions. On high of the efficient architecture of DeepSeek-V2, we pioneer an auxiliary-loss-Free DeepSeek Chat technique for load balancing, which minimizes the performance degradation that arises from encouraging load balancing. Persons are very hungry for higher price efficiency. Longer Reasoning, Better Performance. The extra efficiency comes at the cost of slower and dearer output. That mixture of performance and decrease value helped DeepSeek's AI assistant turn into probably the most-downloaded free app on Apple's App Store when it was released within the US. On Jan. 10, it released its first free chatbot app, which was based mostly on a brand new model referred to as DeepSeek-V3. It is reportedly as highly effective as OpenAI's o1 mannequin - released at the tip of last yr - in duties together with mathematics and coding. Additionally, DeepSeek-V2.5 has seen vital enhancements in tasks similar to writing and instruction-following. DeepSeek-R1-Lite-Preview reveals regular score enhancements on AIME as thought length increases. This extends the context length from 4K to 16K. This produced the bottom models. At an economical cost of solely 2.664M H800 GPU hours, we full the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the at present strongest open-supply base model.
We directly apply reinforcement learning (RL) to the base mannequin without relying on supervised tremendous-tuning (SFT) as a preliminary step. Amazon SageMaker JumpStart is a machine studying (ML) hub with FMs, constructed-in algorithms, and prebuilt ML solutions which you could deploy with only a few clicks. It has been attempting to recruit deep studying scientists by providing annual salaries of as much as 2 million Yuan. At solely $5.5 million to prepare, it’s a fraction of the cost of fashions from OpenAI, Google, or Anthropic which are often in the hundreds of hundreds of thousands. Many pundits identified that DeepSeek’s $6 million covered solely what the beginning-up spent when coaching the final model of the system. For example, RL on reasoning might improve over more training steps. Alternatively, ChatGPT, for example, actually understood the which means behind the picture: "This metaphor suggests that the mom's attitudes, phrases, or values are directly influencing the kid's actions, particularly in a unfavourable method corresponding to bullying or discrimination," it concluded-accurately, shall we add. For instance, a system with DDR5-5600 providing round ninety GBps might be sufficient. The system immediate asked R1 to reflect and confirm during considering.
Avoid adding a system immediate; all instructions should be contained throughout the person immediate. But the workforce behind the new system also revealed a bigger step ahead. Models are pre-skilled using 1.8T tokens and a 4K window size in this step. 5) The output token rely of deepseek-reasoner contains all tokens from CoT and the final answer, and they are priced equally. After having 2T extra tokens than each. In different phrases, it saved many more decimals. Through co-design of algorithms, frameworks, and hardware, we overcome the communication bottleneck in cross-node MoE coaching, almost attaining full computation-communication overlap. To realize environment friendly inference and cost-efficient coaching, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which have been thoroughly validated in DeepSeek-V2. The University of Waterloo Tiger Lab's leaderboard ranked DeepSeek-V2 seventh on its LLM rating. In key areas corresponding to reasoning, coding, mathematics, and Chinese comprehension, LLM outperforms other language models. Both High-Flyer and Deepseek free are run by Liang Wenfeng, a Chinese entrepreneur. This leads us to Chinese AI startup DeepSeek. MATH-500: DeepSeek V3 leads with 90.2 (EM), outperforming others. As DeepSeek engineers detailed in a analysis paper revealed simply after Christmas, the beginning-up used several technological methods to significantly scale back the price of building its system.
If you loved this article and you would like to receive more info with regards to Deepseek AI Online Chat please visit our own webpage.