
 The Nvidia Factor: How Did DeepSeek Build Its Model? The low cost of coaching and running the language mannequin was attributed to Chinese companies' lack of access to Nvidia chipsets, which have been restricted by the US as a part of the continuing commerce battle between the two international locations. 2) For factuality benchmarks, DeepSeek-V3 demonstrates superior efficiency amongst open-source fashions on each SimpleQA and Chinese SimpleQA. In the course of the pre-coaching stage, training DeepSeek-V3 on every trillion tokens requires solely 180K H800 GPU hours, i.e., 3.7 days on our cluster with 2048 H800 GPUs. For every token, when its routing resolution is made, it will first be transmitted via IB to the GPUs with the identical in-node index on its target nodes. ". But, reinventing the wheel is the way you find out how things work, and is step one to make new, totally different wheels. Models are pre-educated utilizing 1.8T tokens and a 4K window measurement on this step. Yarn: Efficient context window extension of large language fashions.
The Nvidia Factor: How Did DeepSeek Build Its Model? The low cost of coaching and running the language mannequin was attributed to Chinese companies' lack of access to Nvidia chipsets, which have been restricted by the US as a part of the continuing commerce battle between the two international locations. 2) For factuality benchmarks, DeepSeek-V3 demonstrates superior efficiency amongst open-source fashions on each SimpleQA and Chinese SimpleQA. In the course of the pre-coaching stage, training DeepSeek-V3 on every trillion tokens requires solely 180K H800 GPU hours, i.e., 3.7 days on our cluster with 2048 H800 GPUs. For every token, when its routing resolution is made, it will first be transmitted via IB to the GPUs with the identical in-node index on its target nodes. ". But, reinventing the wheel is the way you find out how things work, and is step one to make new, totally different wheels. Models are pre-educated utilizing 1.8T tokens and a 4K window measurement on this step. Yarn: Efficient context window extension of large language fashions.
For the MoE half, we use 32-means Expert Parallelism (EP32), which ensures that each expert processes a sufficiently giant batch dimension, thereby enhancing computational efficiency. Particularly, we use 1-manner Tensor Parallelism for the dense MLPs in shallow layers to avoid wasting TP communication. All-to-all communication of the dispatch and combine parts is performed through direct point-to-point transfers over IB to realize low latency. To be particular, we divide each chunk into four parts: consideration, all-to-all dispatch, MLP, and all-to-all mix. • Executing cut back operations for all-to-all mix. • We examine a Multi-Token Prediction (MTP) objective and prove it helpful to model performance. Secondly, Free DeepSeek Ai Chat-V3 employs a multi-token prediction training goal, which we have now noticed to enhance the general performance on analysis benchmarks. DeepSeek-V3-Base and DeepSeek-V3 (a chat mannequin) use basically the identical architecture as V2 with the addition of multi-token prediction, which (optionally) decodes further tokens quicker but much less accurately. In the remainder of this paper, we first present an in depth exposition of our DeepSeek v3-V3 mannequin architecture (Section 2). Subsequently, we introduce our infrastructures, encompassing our compute clusters, the training framework, the assist for FP8 coaching, the inference deployment technique, and our suggestions on future hardware design.
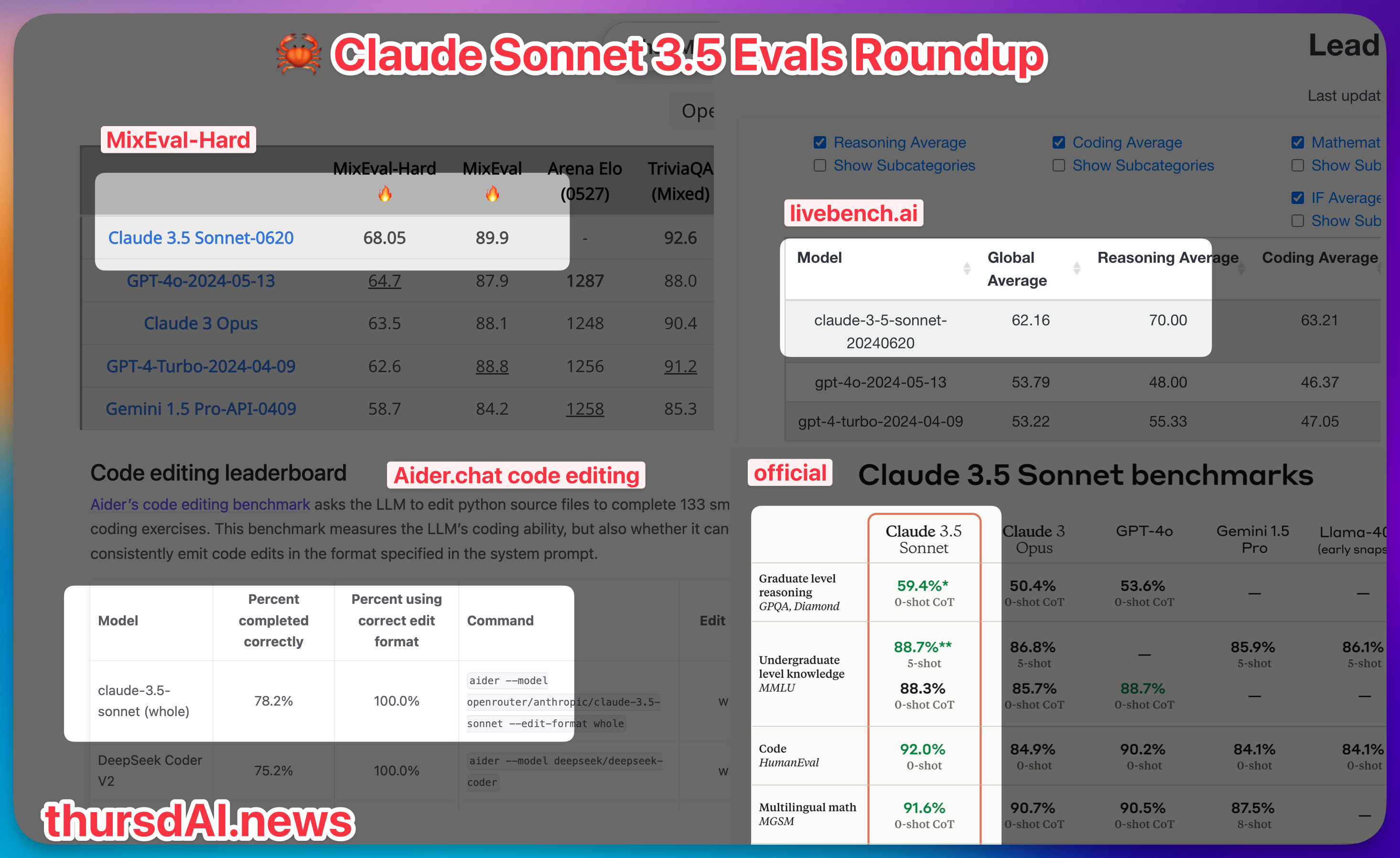 Figure 2 illustrates the essential structure of DeepSeek-V3, and we'll briefly assessment the main points of MLA and DeepSeekMoE on this section. For the second problem, we also design and implement an environment friendly inference framework with redundant knowledgeable deployment, as described in Section 3.4, to beat it. Firstly, we design the DualPipe algorithm for efficient pipeline parallelism. The attention part employs 4-means Tensor Parallelism (TP4) with Sequence Parallelism (SP), combined with 8-means Data Parallelism (DP8). For that reason, after careful investigations, we maintain the original precision (e.g., BF16 or FP32) for the next elements: the embedding module, the output head, MoE gating modules, normalization operators, and a spotlight operators. Specially, for a backward chunk, each consideration and MLP are additional cut up into two parts, backward for enter and backward for weights, like in ZeroBubble (Qi et al., 2023b). As well as, now we have a PP communication element. DeepSeek, like OpenAI's ChatGPT, is a chatbot fueled by an algorithm that selects phrases based on lessons discovered from scanning billions of pieces of text across the web. Its performance is comparable to main closed-source fashions like GPT-4o and Claude-Sonnet-3.5, narrowing the gap between open-supply and closed-supply models in this domain.
Figure 2 illustrates the essential structure of DeepSeek-V3, and we'll briefly assessment the main points of MLA and DeepSeekMoE on this section. For the second problem, we also design and implement an environment friendly inference framework with redundant knowledgeable deployment, as described in Section 3.4, to beat it. Firstly, we design the DualPipe algorithm for efficient pipeline parallelism. The attention part employs 4-means Tensor Parallelism (TP4) with Sequence Parallelism (SP), combined with 8-means Data Parallelism (DP8). For that reason, after careful investigations, we maintain the original precision (e.g., BF16 or FP32) for the next elements: the embedding module, the output head, MoE gating modules, normalization operators, and a spotlight operators. Specially, for a backward chunk, each consideration and MLP are additional cut up into two parts, backward for enter and backward for weights, like in ZeroBubble (Qi et al., 2023b). As well as, now we have a PP communication element. DeepSeek, like OpenAI's ChatGPT, is a chatbot fueled by an algorithm that selects phrases based on lessons discovered from scanning billions of pieces of text across the web. Its performance is comparable to main closed-source fashions like GPT-4o and Claude-Sonnet-3.5, narrowing the gap between open-supply and closed-supply models in this domain.
The Chat variations of the two Base fashions was launched concurrently, obtained by coaching Base by supervised finetuning (SFT) followed by direct coverage optimization (DPO). We launch the DeepSeek-Prover-V1.5 with 7B parameters, including base, SFT and RL fashions, to the general public. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely by RL, with out the need for SFT. We recompute all RMSNorm operations and MLA up-projections throughout again-propagation, thereby eliminating the need to persistently retailer their output activations. However, we do not must rearrange experts since each GPU only hosts one expert. Within the decoding stage, the batch size per professional is comparatively small (normally within 256 tokens), and the bottleneck is memory entry slightly than computation. • Through the co-design of algorithms, frameworks, and hardware, we overcome the communication bottleneck in cross-node MoE coaching, reaching near-full computation-communication overlap. In addition, we also develop efficient cross-node all-to-all communication kernels to fully make the most of InfiniBand (IB) and NVLink bandwidths. Overall, under such a communication strategy, only 20 SMs are sufficient to fully utilize the bandwidths of IB and NVLink. The key thought of DualPipe is to overlap the computation and communication within a pair of individual ahead and backward chunks.
Should you beloved this article along with you would like to receive more information with regards to DeepSeek Ai Chat (https://vocal.media) i implore you to stop by our webpage.