
.png) So, principally, it’s a type of pink teaming, but it is a type of red teaming of the methods themselves quite than of particular fashions. Connect the output (pink edge) of the InputPrompt node to the enter (inexperienced edge) of the LLM node. This script allows users to specify a title, immediate, image dimension, and output directory. Leike: Basically, when you have a look at how programs are being aligned as we speak, which is using reinforcement studying from human suggestions (RLHF)-on a excessive degree, the way in which it works is you will have the system do a bunch of issues, say, write a bunch of various responses to no matter prompt the consumer places into ChatGPT, and then you definitely ask a human which one is best. And there’s a bunch of ideas and methods that have been proposed through the years: recursive reward modeling, debate, activity decomposition, and so forth. So for example, sooner or later if you have GPT-5 or 6 and also you ask it to write down a code base, there’s just no manner we’ll find all the problems with the code base. So if you just use RLHF, you wouldn’t actually practice the system to put in writing a bug-free code base.
So, principally, it’s a type of pink teaming, but it is a type of red teaming of the methods themselves quite than of particular fashions. Connect the output (pink edge) of the InputPrompt node to the enter (inexperienced edge) of the LLM node. This script allows users to specify a title, immediate, image dimension, and output directory. Leike: Basically, when you have a look at how programs are being aligned as we speak, which is using reinforcement studying from human suggestions (RLHF)-on a excessive degree, the way in which it works is you will have the system do a bunch of issues, say, write a bunch of various responses to no matter prompt the consumer places into ChatGPT, and then you definitely ask a human which one is best. And there’s a bunch of ideas and methods that have been proposed through the years: recursive reward modeling, debate, activity decomposition, and so forth. So for example, sooner or later if you have GPT-5 or 6 and also you ask it to write down a code base, there’s just no manner we’ll find all the problems with the code base. So if you just use RLHF, you wouldn’t actually practice the system to put in writing a bug-free code base.
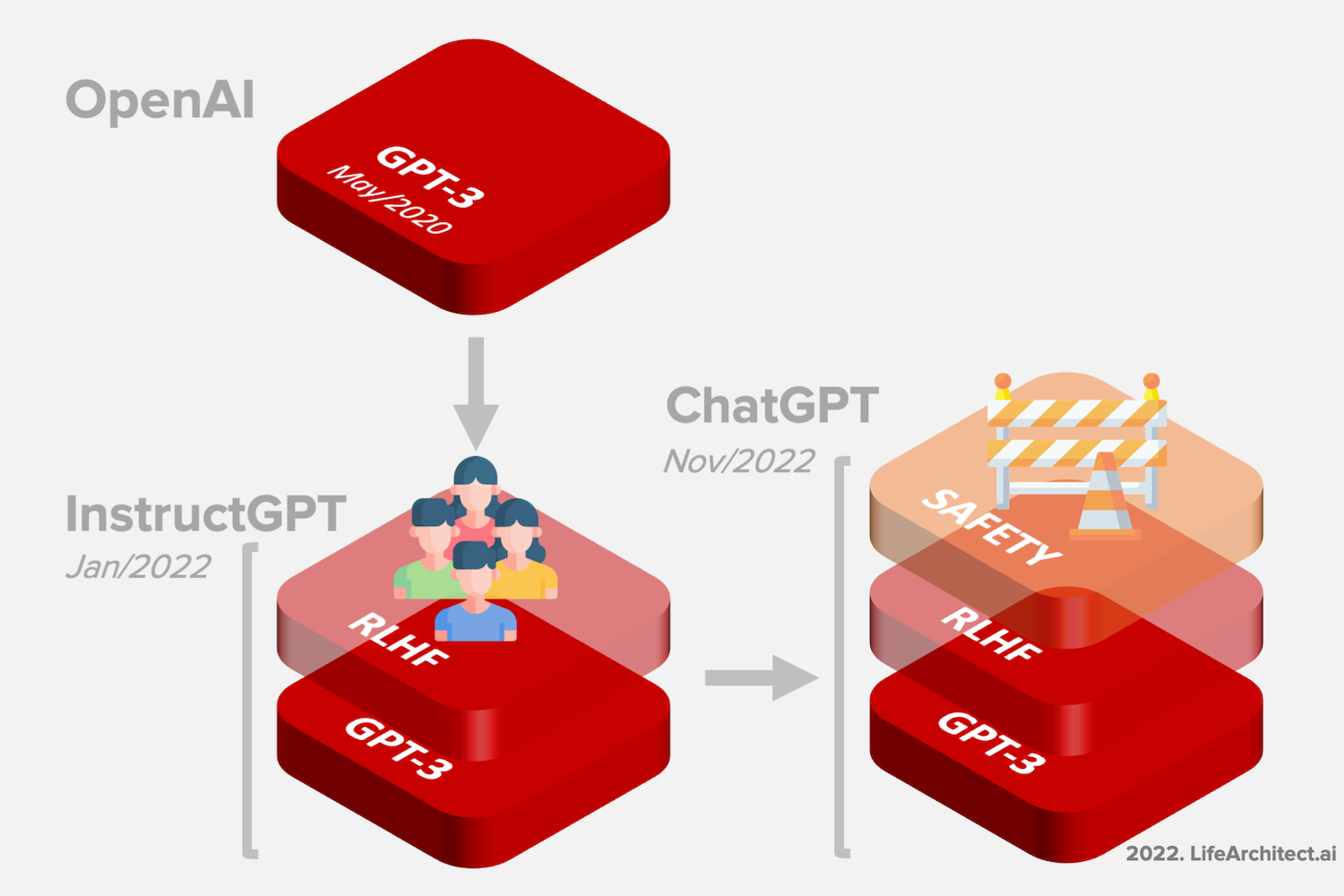 Large Language Models (LLMs) are a type of synthetic intelligence system that is skilled on vast quantities of textual content knowledge, allowing them to generate human-like responses, perceive and process pure language, and perform a variety of language-associated tasks. A coherently designed kernel, libc, and base system written from scratch. And I feel that is a lesson for lots of brands which can be small, medium enterprises, thinking around attention-grabbing ways to interact individuals and create some kind of intrigue, intrigue, is that the key word there. In this blog we're going to debate the other ways you should utilize docker in your homelab. You're welcome, however was there actually version called 20c? Only the digital model will likely be available in the mean time. And if you may work out how to try this well, then human evaluation or assisted human analysis will get better because the models get extra succesful, proper? The goal right here is to basically get a feel of the Rust language with a selected project and objective in mind, whilst additionally learning ideas round File I/O, mutability, dealing with the dreaded borrow checker, vectors, modules, exterior crates and so forth.
Large Language Models (LLMs) are a type of synthetic intelligence system that is skilled on vast quantities of textual content knowledge, allowing them to generate human-like responses, perceive and process pure language, and perform a variety of language-associated tasks. A coherently designed kernel, libc, and base system written from scratch. And I feel that is a lesson for lots of brands which can be small, medium enterprises, thinking around attention-grabbing ways to interact individuals and create some kind of intrigue, intrigue, is that the key word there. In this blog we're going to debate the other ways you should utilize docker in your homelab. You're welcome, however was there actually version called 20c? Only the digital model will likely be available in the mean time. And if you may work out how to try this well, then human evaluation or assisted human analysis will get better because the models get extra succesful, proper? The goal right here is to basically get a feel of the Rust language with a selected project and objective in mind, whilst additionally learning ideas round File I/O, mutability, dealing with the dreaded borrow checker, vectors, modules, exterior crates and so forth.
Evaluating the efficiency of prompts is essential for ensuring that language models like ChatGPT produce accurate and contextually relevant responses. If you’re utilizing an outdated browser or machine with limited assets, it can lead to performance issues or unexpected habits when interacting with ChatGPT. And it’s not prefer it by no means helps, however on common, it doesn’t help enough to warrant utilizing it for our research. Plus, I’ll offer you suggestions, tools, and plenty of examples to indicate you the way it’s performed. Furthermore, they present that fairer preferences result in larger correlations with human judgments. After which the model might say, "Well, I actually care about human flourishing." But then how do you realize it actually does, and it didn’t simply lie to you? At this level, the model might inform from the numbers the actual state of each firm. And you may choose the duty of: Tell me what your goal is. The foundational task underpinning the coaching of most cutting-edge LLMs revolves around phrase prediction, predicting the probability distribution of the subsequent word given a sequence. But this assumes that the human is aware of exactly how the task works and what the intent was and what an excellent reply appears like.
We're actually excited to chat gbt try them empirically and see how properly they work, and we predict we now have pretty good ways to measure whether or not we’re making progress on this, even if the duty is hard. Well-defined and consistent habits are the glue that keep you rising and efficient, even when your motivation wanes. Can you speak a little bit bit about why that’s helpful and whether or not there are risks concerned? And then you can examine them and say, okay, how can we tell the difference? Can you inform me about scalable human oversight? The idea behind scalable oversight is to figure out how to use AI to assist human analysis. After which, the third stage is a superintelligent AI that decides to wipe out humanity. Another level is something that tells you tips on how to make a bioweapon. So that’s one degree of misalignment. For one thing like writing code, if there is a bug that’s a binary, it's or it isn’t. And part of it is that there isn’t that much pretraining information for alignment. How do you work towards extra philosophical types of alignment? It's going to probably work better.
If you have any inquiries with regards to the place and how to use chat gpt Free, you can get in touch with us at our own web-page.