
 How can I get assist or ask questions on DeepSeek Coder? Assuming you may have a chat mannequin set up already (e.g. Codestral, Llama 3), you possibly can keep this complete expertise native by offering a hyperlink to the Ollama README on GitHub and asking questions to study more with it as context. The LLM was educated on a large dataset of two trillion tokens in each English and Chinese, using architectures resembling LLaMA and Grouped-Query Attention. Capabilities: Code Llama redefines coding assistance with its groundbreaking capabilities. Notably, it even outperforms o1-preview on particular benchmarks, such as MATH-500, demonstrating its strong mathematical reasoning capabilities. This mannequin is a blend of the spectacular Hermes 2 Pro and Meta's Llama-three Instruct, resulting in a powerhouse that excels typically duties, conversations, and even specialised features like calling APIs and generating structured JSON knowledge. Whether it is enhancing conversations, generating creative content, or providing detailed analysis, these models really creates a big influence. Its efficiency is comparable to leading closed-source fashions like GPT-4o and Claude-Sonnet-3.5, narrowing the hole between open-supply and closed-source models in this domain. 2) On coding-related tasks, DeepSeek-V3 emerges as the top-performing mannequin for coding competitors benchmarks, comparable to LiveCodeBench, solidifying its position because the leading model in this area.
How can I get assist or ask questions on DeepSeek Coder? Assuming you may have a chat mannequin set up already (e.g. Codestral, Llama 3), you possibly can keep this complete expertise native by offering a hyperlink to the Ollama README on GitHub and asking questions to study more with it as context. The LLM was educated on a large dataset of two trillion tokens in each English and Chinese, using architectures resembling LLaMA and Grouped-Query Attention. Capabilities: Code Llama redefines coding assistance with its groundbreaking capabilities. Notably, it even outperforms o1-preview on particular benchmarks, such as MATH-500, demonstrating its strong mathematical reasoning capabilities. This mannequin is a blend of the spectacular Hermes 2 Pro and Meta's Llama-three Instruct, resulting in a powerhouse that excels typically duties, conversations, and even specialised features like calling APIs and generating structured JSON knowledge. Whether it is enhancing conversations, generating creative content, or providing detailed analysis, these models really creates a big influence. Its efficiency is comparable to leading closed-source fashions like GPT-4o and Claude-Sonnet-3.5, narrowing the hole between open-supply and closed-source models in this domain. 2) On coding-related tasks, DeepSeek-V3 emerges as the top-performing mannequin for coding competitors benchmarks, comparable to LiveCodeBench, solidifying its position because the leading model in this area.
 Its chat model additionally outperforms different open-source fashions and achieves performance comparable to leading closed-source fashions, together with GPT-4o and Claude-3.5-Sonnet, on a series of commonplace and open-ended benchmarks. While it trails behind GPT-4o and Claude-Sonnet-3.5 in English factual data (SimpleQA), it surpasses these fashions in Chinese factual information (Chinese SimpleQA), highlighting its strength in Chinese factual knowledge. Through the dynamic adjustment, DeepSeek-V3 retains balanced expert load throughout coaching, and achieves higher efficiency than fashions that encourage load stability by way of pure auxiliary losses. These two architectures have been validated in DeepSeek-V2 (DeepSeek-AI, 2024c), demonstrating their functionality to keep up robust model performance whereas achieving efficient training and inference. In case your system does not have fairly sufficient RAM to fully load the model at startup, you'll be able to create a swap file to help with the loading. Should you intend to construct a multi-agent system, Camel could be among the finest choices accessible in the open-supply scene.
Its chat model additionally outperforms different open-source fashions and achieves performance comparable to leading closed-source fashions, together with GPT-4o and Claude-3.5-Sonnet, on a series of commonplace and open-ended benchmarks. While it trails behind GPT-4o and Claude-Sonnet-3.5 in English factual data (SimpleQA), it surpasses these fashions in Chinese factual information (Chinese SimpleQA), highlighting its strength in Chinese factual knowledge. Through the dynamic adjustment, DeepSeek-V3 retains balanced expert load throughout coaching, and achieves higher efficiency than fashions that encourage load stability by way of pure auxiliary losses. These two architectures have been validated in DeepSeek-V2 (DeepSeek-AI, 2024c), demonstrating their functionality to keep up robust model performance whereas achieving efficient training and inference. In case your system does not have fairly sufficient RAM to fully load the model at startup, you'll be able to create a swap file to help with the loading. Should you intend to construct a multi-agent system, Camel could be among the finest choices accessible in the open-supply scene.
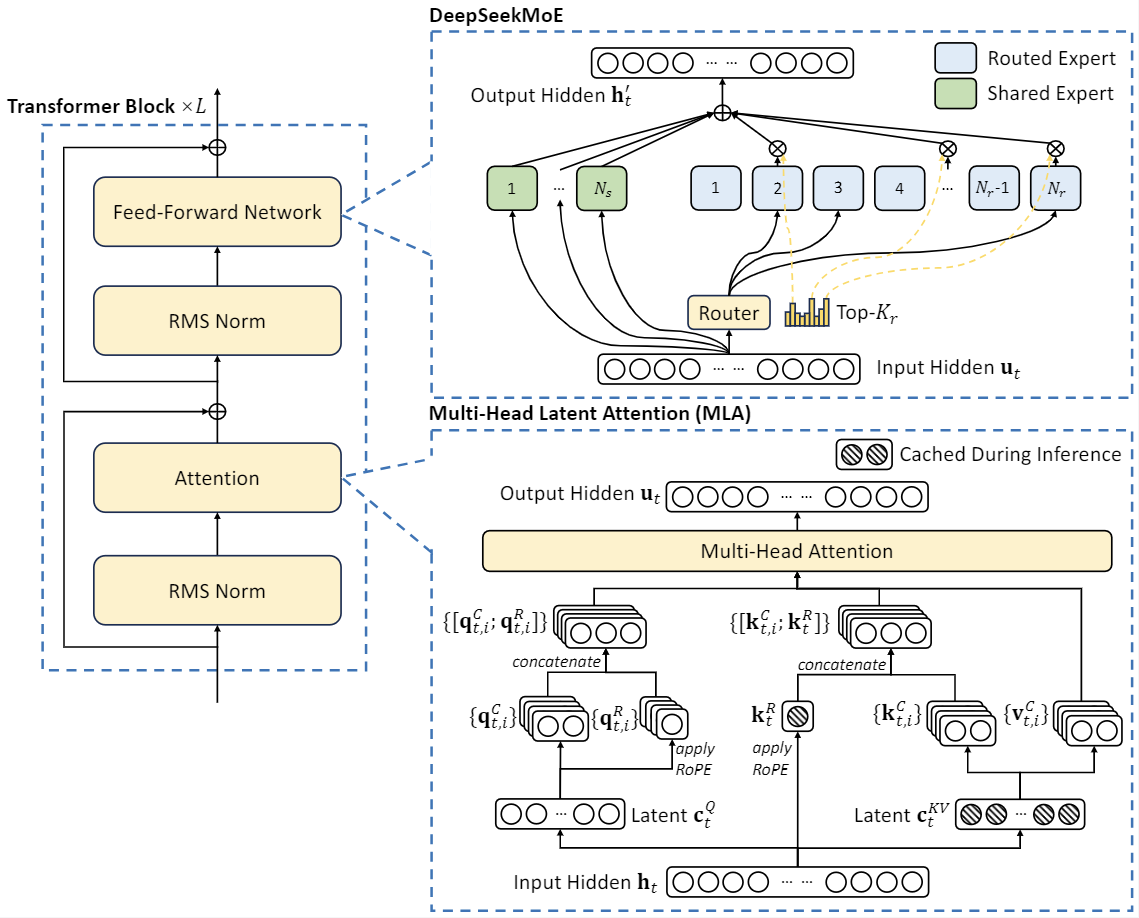
For greatest efficiency, a trendy multi-core CPU is really useful. One of the best half? There’s no mention of machine studying, LLMs, or neural nets throughout the paper. Why this issues - intelligence is the most effective protection: Research like this each highlights the fragility of LLM know-how as well as illustrating how as you scale up LLMs they appear to change into cognitively capable enough to have their very own defenses in opposition to weird attacks like this. Then, we present a Multi-Token Prediction (MTP) training objective, which we now have observed to enhance the general efficiency on analysis benchmarks. • We investigate a Multi-Token Prediction (MTP) goal and prove it beneficial to mannequin performance. Secondly, DeepSeek-V3 employs a multi-token prediction coaching goal, which we've got noticed to reinforce the general efficiency on evaluation benchmarks. For Feed-Forward Networks (FFNs), DeepSeek-V3 employs the DeepSeekMoE structure (Dai et al., 2024). Compared with traditional MoE architectures like GShard (Lepikhin et al., 2021), DeepSeekMoE makes use of finer-grained specialists and isolates some consultants as shared ones.
Figure 2 illustrates the fundamental structure of DeepSeek-V3, and we are going to briefly review the main points of MLA and DeepSeekMoE in this section. Figure three illustrates our implementation of MTP. On the one hand, an MTP goal densifies the training signals and will improve knowledge efficiency. On the other hand, MTP may allow the model to pre-plan its representations for higher prediction of future tokens. D extra tokens utilizing unbiased output heads, we sequentially predict additional tokens and keep the entire causal chain at every prediction depth. Meanwhile, we also maintain management over the output model and length of free deepseek-V3. Throughout the pre-training stage, training DeepSeek-V3 on each trillion tokens requires only 180K H800 GPU hours, i.e., 3.7 days on our cluster with 2048 H800 GPUs. Despite its economical coaching costs, comprehensive evaluations reveal that DeepSeek-V3-Base has emerged as the strongest open-source base mannequin at the moment accessible, especially in code and math. So as to attain environment friendly training, we help the FP8 combined precision coaching and implement complete optimizations for the training framework. We consider DeepSeek-V3 on a complete array of benchmarks. • At an economical cost of solely 2.664M H800 GPU hours, we complete the pre-coaching of free deepseek-V3 on 14.8T tokens, producing the at the moment strongest open-source base model.
If you cherished this report and you would like to get far more information regarding ديب سيك kindly take a look at our own web-page.