
 Meaning DeepSeek was in a position to achieve its low-cost mannequin on underneath-powered AI chips. Comprehensive evaluations demonstrate that DeepSeek-V3 has emerged as the strongest open-supply mannequin currently available, and achieves performance comparable to leading closed-source models like GPT-4o and Claude-3.5-Sonnet. Similarly, DeepSeek-V3 showcases distinctive efficiency on AlpacaEval 2.0, outperforming each closed-supply and open-source models. This achievement considerably bridges the performance hole between open-supply and closed-source models, setting a brand new commonplace for what open-supply models can accomplish in difficult domains. This success may be attributed to its superior information distillation technique, which successfully enhances its code generation and problem-fixing capabilities in algorithm-centered duties. DeepSeek Coder is skilled from scratch on each 87% code and 13% natural language in English and Chinese. Qwen and DeepSeek are two representative mannequin collection with strong assist for both Chinese and English. The paper attributes the robust mathematical reasoning capabilities of DeepSeekMath 7B to 2 key factors: the extensive math-related data used for pre-training and the introduction of the GRPO optimization approach.
Meaning DeepSeek was in a position to achieve its low-cost mannequin on underneath-powered AI chips. Comprehensive evaluations demonstrate that DeepSeek-V3 has emerged as the strongest open-supply mannequin currently available, and achieves performance comparable to leading closed-source models like GPT-4o and Claude-3.5-Sonnet. Similarly, DeepSeek-V3 showcases distinctive efficiency on AlpacaEval 2.0, outperforming each closed-supply and open-source models. This achievement considerably bridges the performance hole between open-supply and closed-source models, setting a brand new commonplace for what open-supply models can accomplish in difficult domains. This success may be attributed to its superior information distillation technique, which successfully enhances its code generation and problem-fixing capabilities in algorithm-centered duties. DeepSeek Coder is skilled from scratch on each 87% code and 13% natural language in English and Chinese. Qwen and DeepSeek are two representative mannequin collection with strong assist for both Chinese and English. The paper attributes the robust mathematical reasoning capabilities of DeepSeekMath 7B to 2 key factors: the extensive math-related data used for pre-training and the introduction of the GRPO optimization approach.
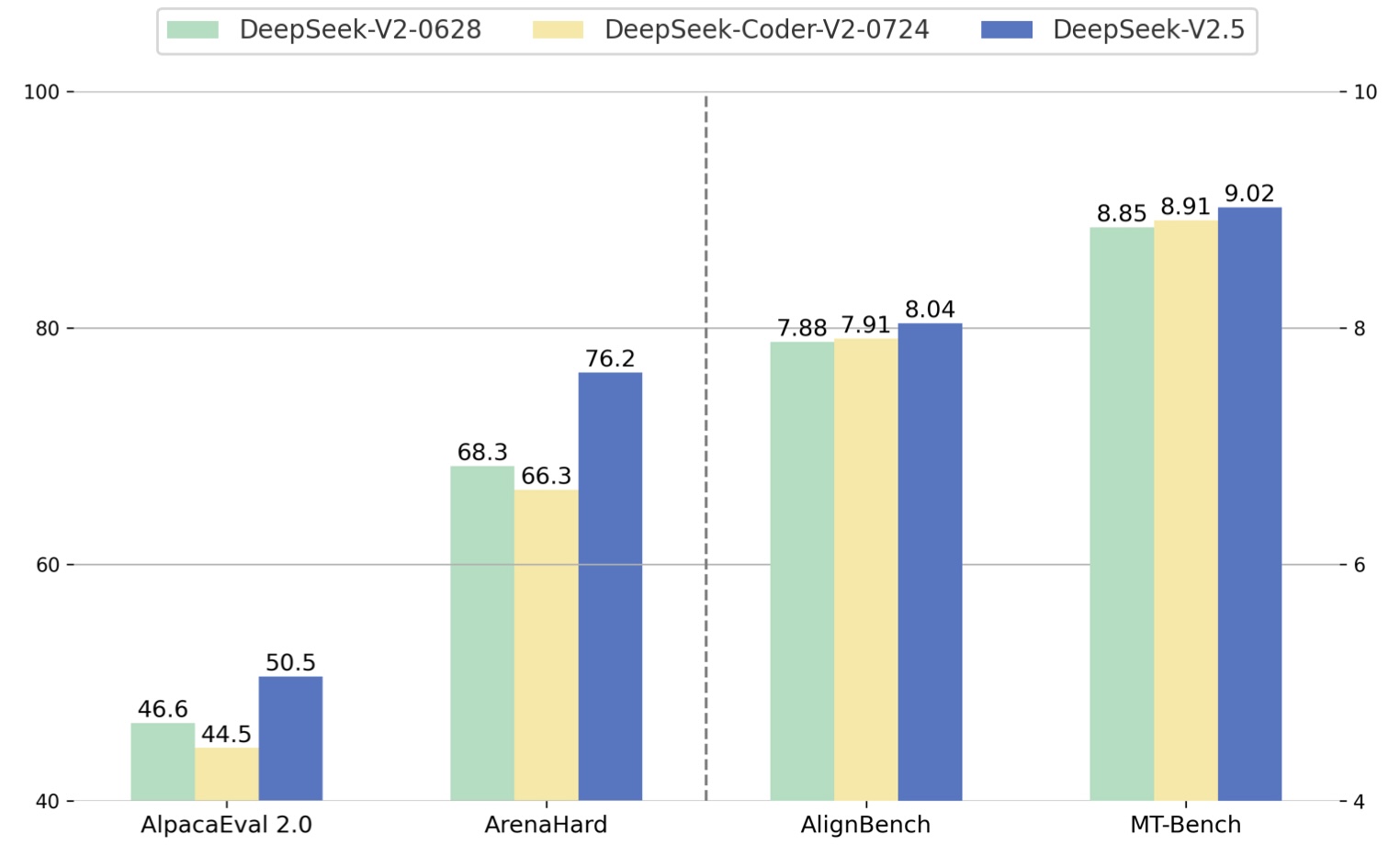
• We are going to discover more comprehensive and multi-dimensional mannequin evaluation methods to forestall the tendency in the direction of optimizing a hard and fast set of benchmarks during analysis, which may create a deceptive impression of the mannequin capabilities and have an effect on our foundational evaluation. During the development of DeepSeek-V3, for these broader contexts, we employ the constitutional AI strategy (Bai et al., 2022), leveraging the voting analysis results of DeepSeek-V3 itself as a feedback source. As well as to straightforward benchmarks, we also evaluate our fashions on open-ended technology duties using LLMs as judges, with the outcomes proven in Table 7. Specifically, we adhere to the original configurations of AlpacaEval 2.Zero (Dubois et al., 2024) and Arena-Hard (Li et al., 2024a), which leverage GPT-4-Turbo-1106 as judges for pairwise comparisons. To test our understanding, we’ll carry out a few easy coding tasks, and examine the various strategies in achieving the desired results and also show the shortcomings. In domains where verification via exterior tools is simple, corresponding to some coding or mathematics situations, RL demonstrates exceptional efficacy.
 While our current work focuses on distilling knowledge from arithmetic and coding domains, this strategy reveals potential for broader functions across various task domains. Learn how to put in DeepSeek-R1 domestically for coding and logical drawback-fixing, no monthly charges, no knowledge leaks. • We'll continuously iterate on the amount and high quality of our training information, and explore the incorporation of further training sign sources, aiming to drive knowledge scaling across a more comprehensive vary of dimensions. • We will constantly examine and refine our model architectures, aiming to additional enhance each the training and inference efficiency, striving to approach environment friendly support for infinite context length. Additionally, you will must be careful to choose a mannequin that might be responsive utilizing your GPU and that may rely greatly on the specs of your GPU. It requires solely 2.788M H800 GPU hours for its full coaching, including pre-coaching, context size extension, and post-coaching. Our experiments reveal an interesting trade-off: the distillation leads to better performance but also considerably increases the average response length.
While our current work focuses on distilling knowledge from arithmetic and coding domains, this strategy reveals potential for broader functions across various task domains. Learn how to put in DeepSeek-R1 domestically for coding and logical drawback-fixing, no monthly charges, no knowledge leaks. • We'll continuously iterate on the amount and high quality of our training information, and explore the incorporation of further training sign sources, aiming to drive knowledge scaling across a more comprehensive vary of dimensions. • We will constantly examine and refine our model architectures, aiming to additional enhance each the training and inference efficiency, striving to approach environment friendly support for infinite context length. Additionally, you will must be careful to choose a mannequin that might be responsive utilizing your GPU and that may rely greatly on the specs of your GPU. It requires solely 2.788M H800 GPU hours for its full coaching, including pre-coaching, context size extension, and post-coaching. Our experiments reveal an interesting trade-off: the distillation leads to better performance but also considerably increases the average response length.
Table 9 demonstrates the effectiveness of the distillation information, displaying vital enhancements in both LiveCodeBench and MATH-500 benchmarks. The effectiveness demonstrated in these particular areas signifies that long-CoT distillation might be valuable for enhancing model performance in other cognitive duties requiring advanced reasoning. This underscores the robust capabilities of DeepSeek-V3, especially in coping with advanced prompts, including coding and debugging tasks. Additionally, we will attempt to interrupt via the architectural limitations of Transformer, thereby pushing the boundaries of its modeling capabilities. Expert recognition and reward: The brand new model has acquired vital acclaim from trade professionals and AI observers for its efficiency and capabilities. This technique has produced notable alignment effects, significantly enhancing the performance of free deepseek-V3 in subjective evaluations. Therefore, we employ DeepSeek-V3 along with voting to supply self-feedback on open-ended questions, thereby bettering the effectiveness and robustness of the alignment process. Rewards play a pivotal function in RL, steering the optimization course of. Our analysis means that information distillation from reasoning fashions presents a promising course for put up-training optimization. Further exploration of this strategy throughout totally different domains stays an essential course for future analysis. Secondly, though our deployment strategy for DeepSeek-V3 has achieved an end-to-end generation pace of greater than two instances that of DeepSeek-V2, there still remains potential for further enhancement.