
India is developing a generative AI mannequin with 18,000 GPUs, aiming to rival OpenAI and deepseek ai. The most effective is yet to come: "While INTELLECT-1 demonstrates encouraging benchmark results and represents the first mannequin of its dimension efficiently trained on a decentralized network of GPUs, it nonetheless lags behind current state-of-the-artwork fashions educated on an order of magnitude more tokens," they write. Both had vocabulary size 102,400 (byte-level BPE) and context size of 4096. They educated on 2 trillion tokens of English and Chinese text obtained by deduplicating the Common Crawl. In the decoding stage, the batch size per professional is relatively small (normally within 256 tokens), and the bottleneck is memory entry fairly than computation. The baseline is trained on quick CoT data, whereas its competitor makes use of knowledge generated by the expert checkpoints described above. Because of the performance of both the big 70B Llama 3 model as properly because the smaller and self-host-able 8B Llama 3, I’ve really cancelled my ChatGPT subscription in favor of Open WebUI, a self-hostable ChatGPT-like UI that allows you to use Ollama and different AI providers while conserving your chat history, prompts, and different information locally on any computer you management.
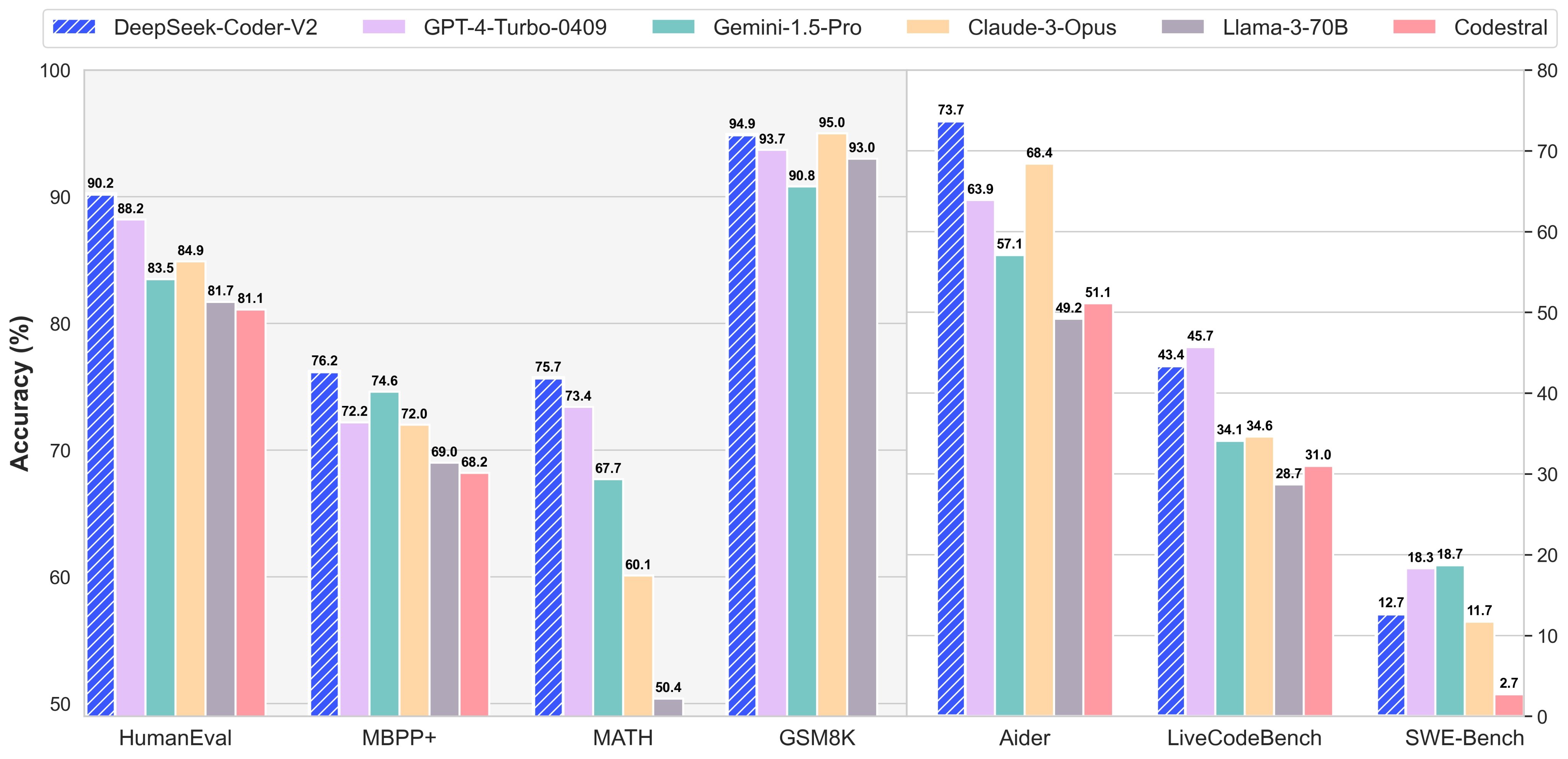 By following these steps, you may easily combine multiple OpenAI-appropriate APIs with your Open WebUI instance, unlocking the total potential of those powerful AI models. The purpose of this publish is to deep-dive into LLM’s which are specialised in code era duties, and see if we will use them to put in writing code. AI Models having the ability to generate code unlocks all sorts of use cases. Benchmark tests point out that deepseek ai china-V3 outperforms fashions like Llama 3.1 and Qwen 2.5, whereas matching the capabilities of GPT-4o and Claude 3.5 Sonnet. They even assist Llama three 8B! They provide native help for Python and Javascript. OpenAI is the instance that is most often used all through the Open WebUI docs, nevertheless they can assist any variety of OpenAI-appropriate APIs. Here’s Llama three 70B running in actual time on Open WebUI. Their claim to fame is their insanely quick inference instances - sequential token era in the hundreds per second for 70B fashions and 1000's for smaller fashions. All fashions are evaluated in a configuration that limits the output size to 8K. Benchmarks containing fewer than one thousand samples are tested a number of instances utilizing varying temperature settings to derive sturdy remaining results.
By following these steps, you may easily combine multiple OpenAI-appropriate APIs with your Open WebUI instance, unlocking the total potential of those powerful AI models. The purpose of this publish is to deep-dive into LLM’s which are specialised in code era duties, and see if we will use them to put in writing code. AI Models having the ability to generate code unlocks all sorts of use cases. Benchmark tests point out that deepseek ai china-V3 outperforms fashions like Llama 3.1 and Qwen 2.5, whereas matching the capabilities of GPT-4o and Claude 3.5 Sonnet. They even assist Llama three 8B! They provide native help for Python and Javascript. OpenAI is the instance that is most often used all through the Open WebUI docs, nevertheless they can assist any variety of OpenAI-appropriate APIs. Here’s Llama three 70B running in actual time on Open WebUI. Their claim to fame is their insanely quick inference instances - sequential token era in the hundreds per second for 70B fashions and 1000's for smaller fashions. All fashions are evaluated in a configuration that limits the output size to 8K. Benchmarks containing fewer than one thousand samples are tested a number of instances utilizing varying temperature settings to derive sturdy remaining results.
Here’s the limits for my newly created account. Currently Llama 3 8B is the largest mannequin supported, and they have token generation limits a lot smaller than a number of the models obtainable. My previous article went over the best way to get Open WebUI arrange with Ollama and Llama 3, however this isn’t the one means I take advantage of Open WebUI. Now, how do you add all these to your Open WebUI instance? I’ll go over every of them with you and given you the pros and cons of each, then I’ll present you how I arrange all 3 of them in my Open WebUI instance! 14k requests per day is so much, and 12k tokens per minute is considerably increased than the typical individual can use on an interface like Open WebUI. This search may be pluggable into any area seamlessly inside less than a day time for integration. With high intent matching and question understanding expertise, as a enterprise, you could get very nice grained insights into your customers behaviour with search together with their preferences so that you could possibly stock your inventory and manage your catalog in an efficient means. CLUE: A chinese language language understanding analysis benchmark.
Since the release of ChatGPT in November 2023, American AI companies have been laser-targeted on building greater, extra powerful, extra expansive, more energy, and resource-intensive giant language models. One is more aligned with free-market and liberal ideas, and the opposite is extra aligned with egalitarian and professional-authorities values. But you had more combined success with regards to stuff like jet engines and aerospace the place there’s numerous tacit data in there and constructing out every part that goes into manufacturing one thing that’s as wonderful-tuned as a jet engine. If you want to arrange OpenAI for Workers AI yourself, try the guide within the README. This enables you to check out many fashions quickly and successfully for many use instances, such as deepseek ai china Math (model card) for math-heavy tasks and Llama Guard (model card) for moderation duties. This is how I used to be ready to use and consider Llama three as my substitute for ChatGPT! DeepSeek is the title of a free AI-powered chatbot, which looks, feels and works very very like ChatGPT. Anyone who works in AI coverage must be intently following startups like Prime Intellect. That's it. You'll be able to chat with the model within the terminal by coming into the next command.