
 DeepSeek shows that open-source labs have turn into way more efficient at reverse-engineering. This strategy permits fashions to handle totally different features of data extra effectively, improving efficiency and scalability in massive-scale tasks. DeepSeek's AI fashions are distinguished by their cost-effectiveness and effectivity. This efficiency has prompted a re-analysis of the huge investments in AI infrastructure by main tech corporations. However, its knowledge storage practices in China have sparked considerations about privateness and nationwide security, echoing debates round other Chinese tech corporations. This can be a severe problem for corporations whose enterprise relies on promoting models: builders face low switching costs, and DeepSeek’s optimizations provide important financial savings. The open-supply world, up to now, has extra been about the "GPU poors." So if you happen to don’t have a whole lot of GPUs, but you continue to need to get enterprise worth from AI, how are you able to try this? ChatGPT is a fancy, dense mannequin, while DeepSeek uses a extra efficient "Mixture-of-Experts" structure. How it really works: "AutoRT leverages vision-language fashions (VLMs) for scene understanding and grounding, and further makes use of massive language fashions (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots," the authors write. This is exemplified of their DeepSeek-V2 and DeepSeek-Coder-V2 fashions, with the latter broadly regarded as one of the strongest open-source code models out there.
DeepSeek shows that open-source labs have turn into way more efficient at reverse-engineering. This strategy permits fashions to handle totally different features of data extra effectively, improving efficiency and scalability in massive-scale tasks. DeepSeek's AI fashions are distinguished by their cost-effectiveness and effectivity. This efficiency has prompted a re-analysis of the huge investments in AI infrastructure by main tech corporations. However, its knowledge storage practices in China have sparked considerations about privateness and nationwide security, echoing debates round other Chinese tech corporations. This can be a severe problem for corporations whose enterprise relies on promoting models: builders face low switching costs, and DeepSeek’s optimizations provide important financial savings. The open-supply world, up to now, has extra been about the "GPU poors." So if you happen to don’t have a whole lot of GPUs, but you continue to need to get enterprise worth from AI, how are you able to try this? ChatGPT is a fancy, dense mannequin, while DeepSeek uses a extra efficient "Mixture-of-Experts" structure. How it really works: "AutoRT leverages vision-language fashions (VLMs) for scene understanding and grounding, and further makes use of massive language fashions (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots," the authors write. This is exemplified of their DeepSeek-V2 and DeepSeek-Coder-V2 fashions, with the latter broadly regarded as one of the strongest open-source code models out there.
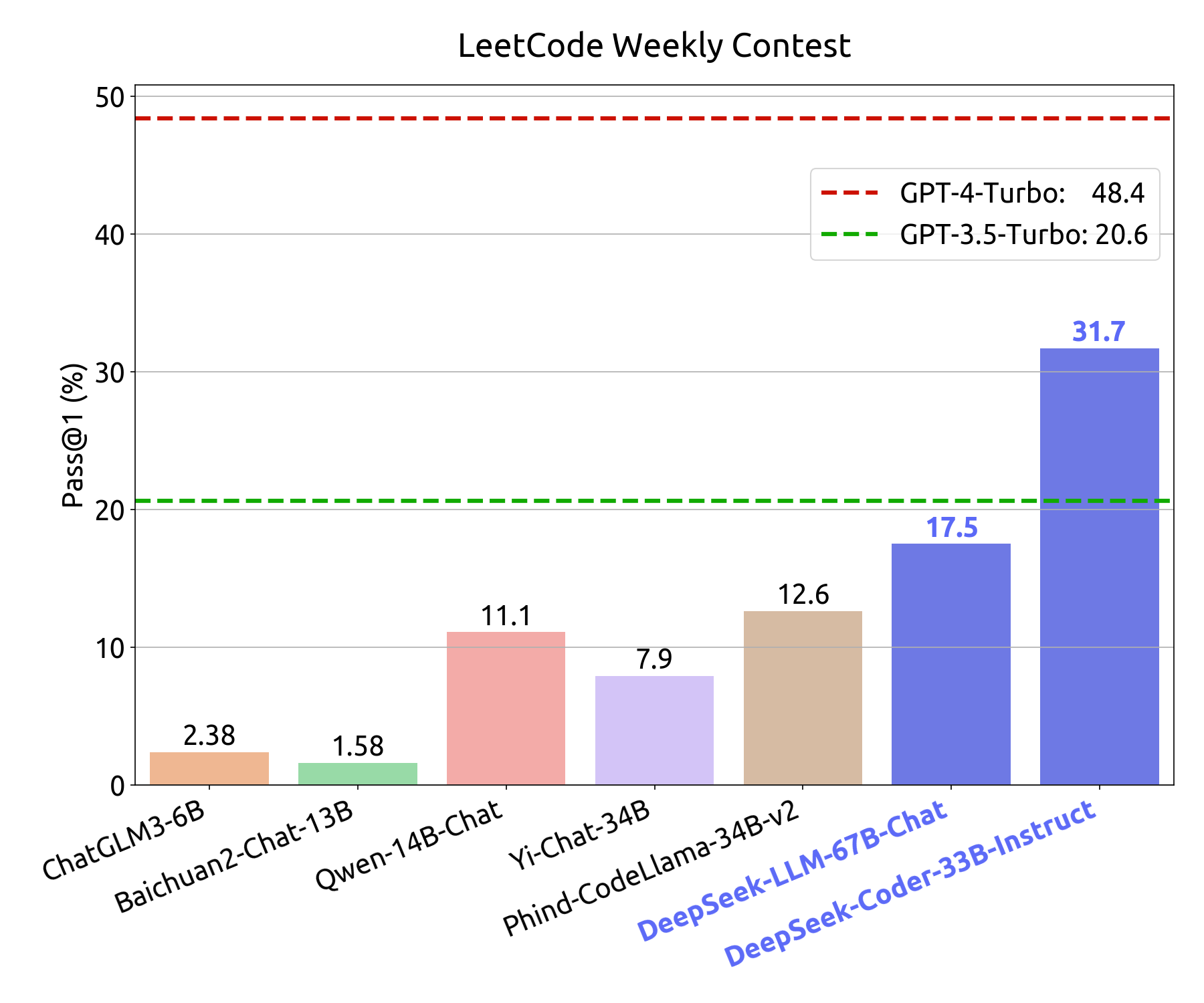
 In a latest growth, the DeepSeek LLM has emerged as a formidable drive in the realm of language fashions, boasting an impressive 67 billion parameters. Both their models, be it DeepSeek-v3 or DeepSeek-R1 have outperformed SOTA fashions by an enormous margin, at about 1/20th price. We ablate the contribution of distillation from DeepSeek-R1 based on DeepSeek-V2.5. Ultimately, we efficiently merged the Chat and Coder fashions to create the new DeepSeek-V2.5. Its built-in chain of thought reasoning enhances its effectivity, making it a strong contender towards different models. 2) CoT (Chain of Thought) is the reasoning content material deepseek-reasoner gives earlier than output the final answer. To address these points and further enhance reasoning efficiency, we introduce DeepSeek-R1, which contains cold-start information before RL. It was skilled using reinforcement studying with out supervised effective-tuning, employing group relative coverage optimization (GRPO) to reinforce reasoning capabilities. Benchmark tests indicate that DeepSeek-V3 outperforms fashions like Llama 3.1 and Qwen 2.5, whereas matching the capabilities of GPT-4o and Claude 3.5 Sonnet. But not like a retail character - not funny or sexy or therapy oriented. Both excel at tasks like coding and writing, with deepseek ai's R1 mannequin rivaling ChatGPT's latest versions.
In a latest growth, the DeepSeek LLM has emerged as a formidable drive in the realm of language fashions, boasting an impressive 67 billion parameters. Both their models, be it DeepSeek-v3 or DeepSeek-R1 have outperformed SOTA fashions by an enormous margin, at about 1/20th price. We ablate the contribution of distillation from DeepSeek-R1 based on DeepSeek-V2.5. Ultimately, we efficiently merged the Chat and Coder fashions to create the new DeepSeek-V2.5. Its built-in chain of thought reasoning enhances its effectivity, making it a strong contender towards different models. 2) CoT (Chain of Thought) is the reasoning content material deepseek-reasoner gives earlier than output the final answer. To address these points and further enhance reasoning efficiency, we introduce DeepSeek-R1, which contains cold-start information before RL. It was skilled using reinforcement studying with out supervised effective-tuning, employing group relative coverage optimization (GRPO) to reinforce reasoning capabilities. Benchmark tests indicate that DeepSeek-V3 outperforms fashions like Llama 3.1 and Qwen 2.5, whereas matching the capabilities of GPT-4o and Claude 3.5 Sonnet. But not like a retail character - not funny or sexy or therapy oriented. Both excel at tasks like coding and writing, with deepseek ai's R1 mannequin rivaling ChatGPT's latest versions.
This mannequin achieves performance comparable to OpenAI's o1 across numerous duties, including arithmetic and coding. Remember, these are suggestions, and the precise performance will rely on a number of components, together with the specific task, mannequin implementation, and different system processes. The DeepSeek model license permits for business usage of the technology beneath specific situations. In addition, we additionally implement specific deployment strategies to ensure inference load steadiness, so DeepSeek-V3 also does not drop tokens throughout inference. It’s their newest mixture of experts (MoE) mannequin skilled on 14.8T tokens with 671B total and 37B active parameters. DeepSeek-V3: Released in late 2024, this mannequin boasts 671 billion parameters and was skilled on a dataset of 14.Eight trillion tokens over approximately 55 days, costing around $5.Fifty eight million. All-to-all communication of the dispatch and mix elements is performed through direct point-to-point transfers over IB to achieve low latency. Then these AI programs are going to have the ability to arbitrarily entry these representations and produce them to life. Going back to the talent loop. Is DeepSeek secure to make use of? It doesn’t let you know all the pieces, and it might not keep your data secure. This raises ethical questions about freedom of information and the potential for AI bias.
Additionally, tech giants Microsoft and OpenAI have launched an investigation into a potential information breach from the group associated with Chinese AI startup deepseek ai. DeepSeek is a Chinese AI startup with a chatbot after it is namesake. 1 spot on Apple’s App Store, pushing OpenAI’s chatbot aside. Additionally, the DeepSeek app is available for download, providing an all-in-one AI software for users. Here’s the most effective part - GroqCloud is free for many customers. DeepSeek's AI fashions are available via its official webpage, where users can entry the DeepSeek-V3 model without spending a dime. Giving everyone entry to highly effective AI has potential to result in security considerations including national safety issues and general consumer security. This fosters a neighborhood-pushed strategy but also raises concerns about potential misuse. Regardless that DeepSeek can be useful sometimes, I don’t suppose it’s a good idea to make use of it. Yes, DeepSeek has fully open-sourced its fashions beneath the MIT license, allowing for unrestricted commercial and educational use. DeepSeek's mission centers on advancing synthetic common intelligence (AGI) through open-supply analysis and improvement, aiming to democratize AI expertise for both business and academic functions. Unravel the mystery of AGI with curiosity. Is DeepSeek's know-how open source? As such, there already seems to be a brand new open supply AI mannequin leader just days after the last one was claimed.