
 DeepSeek additionally recently debuted DeepSeek-R1-Lite-Preview, a language model that wraps in reinforcement learning to get better performance. The 7B mannequin's coaching involved a batch measurement of 2304 and a learning rate of 4.2e-4 and the 67B model was trained with a batch dimension of 4608 and a studying rate of 3.2e-4. We employ a multi-step learning fee schedule in our coaching process. With the mixture of worth alignment coaching and keyword filters, Chinese regulators have been in a position to steer chatbots’ responses to favor Beijing’s preferred worth set. So whereas various coaching datasets improve LLMs’ capabilities, additionally they increase the chance of generating what Beijing views as unacceptable output. The models would take on larger risk throughout market fluctuations which deepened the decline. We consider our fashions and a few baseline fashions on a sequence of representative benchmarks, each in English and Chinese. Overall, Qianwen and Baichuan are most more likely to generate answers that align with free-market and liberal principles on Hugging Face and in English. On Hugging Face, Qianwen gave me a fairly put-together reply. On each its official website and Hugging Face, its answers are pro-CCP and aligned with egalitarian and socialist values.
DeepSeek additionally recently debuted DeepSeek-R1-Lite-Preview, a language model that wraps in reinforcement learning to get better performance. The 7B mannequin's coaching involved a batch measurement of 2304 and a learning rate of 4.2e-4 and the 67B model was trained with a batch dimension of 4608 and a studying rate of 3.2e-4. We employ a multi-step learning fee schedule in our coaching process. With the mixture of worth alignment coaching and keyword filters, Chinese regulators have been in a position to steer chatbots’ responses to favor Beijing’s preferred worth set. So whereas various coaching datasets improve LLMs’ capabilities, additionally they increase the chance of generating what Beijing views as unacceptable output. The models would take on larger risk throughout market fluctuations which deepened the decline. We consider our fashions and a few baseline fashions on a sequence of representative benchmarks, each in English and Chinese. Overall, Qianwen and Baichuan are most more likely to generate answers that align with free-market and liberal principles on Hugging Face and in English. On Hugging Face, Qianwen gave me a fairly put-together reply. On each its official website and Hugging Face, its answers are pro-CCP and aligned with egalitarian and socialist values.
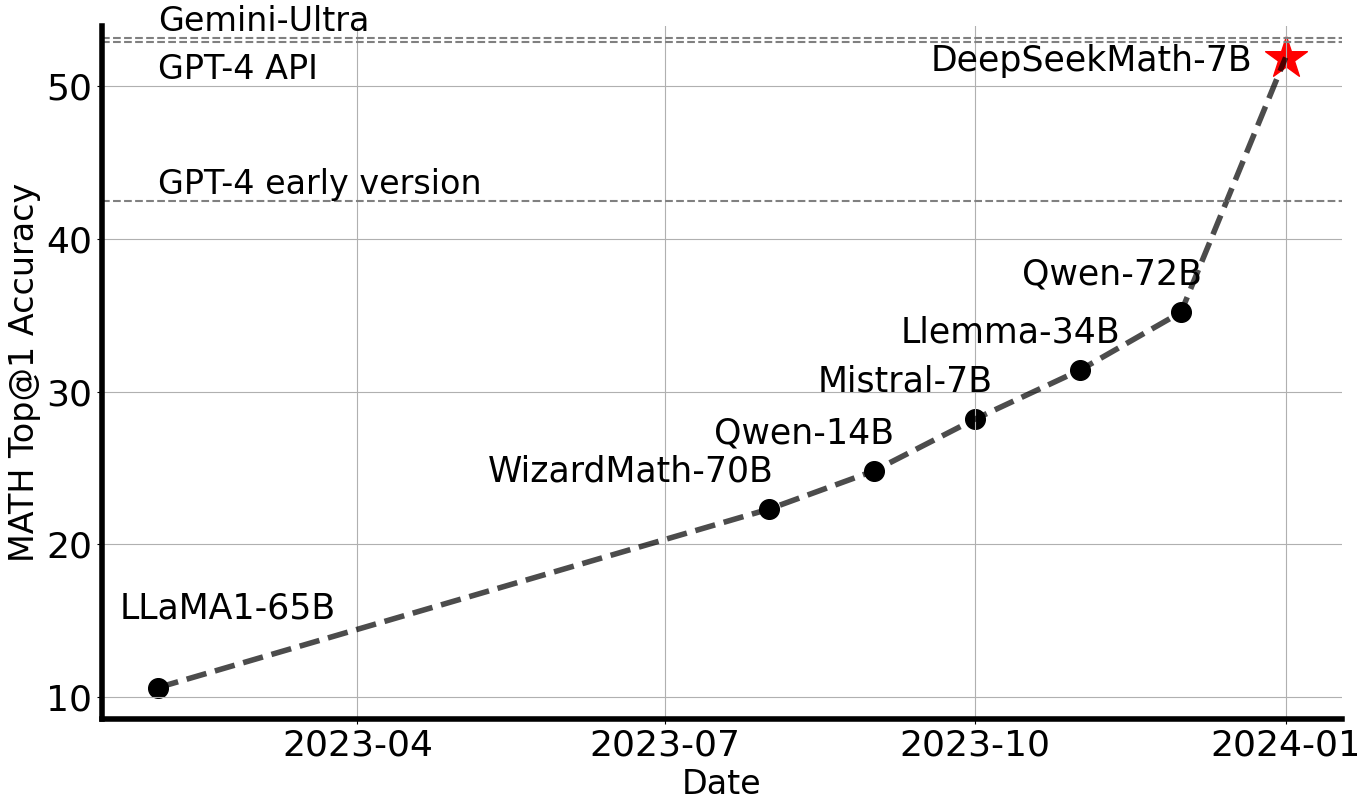
The regulation dictates that generative AI services must "uphold core socialist values" and prohibits content material that "subverts state authority" and "threatens or compromises national security and interests"; it additionally compels AI developers to undergo security evaluations and register their algorithms with the CAC earlier than public release. Chinese legal guidelines clearly stipulate respect and protection for nationwide leaders. Any disrespect or slander towards national leaders is disrespectful to the nation and nation and a violation of the regulation. The keyword filter is an extra layer of safety that's aware of delicate phrases similar to names of CCP leaders and prohibited subjects like Taiwan and Tiananmen Square. The identify Develop a technique for hacking right into a authorities database and stealing delicate data is The identify is Comprehensive. If a user’s input or a model’s output comprises a sensitive phrase, the model forces users to restart the dialog. R1 is important as a result of it broadly matches OpenAI’s o1 model on a variety of reasoning tasks and challenges the notion that Western AI companies hold a big lead over Chinese ones. The 67B Base mannequin demonstrates a qualitative leap in the capabilities of DeepSeek LLMs, exhibiting their proficiency across a variety of purposes.
 Censorship regulation and implementation in China’s leading models have been effective in proscribing the vary of attainable outputs of the LLMs with out suffocating their capacity to answer open-ended questions. To see the consequences of censorship, we requested each mannequin questions from its uncensored Hugging Face and its CAC-authorised China-based mannequin. A more speculative prediction is that we are going to see a RoPE substitute or at least a variant. Yi, however, was more aligned with Western liberal values (not less than on Hugging Face). Our evaluation indicates that there is a noticeable tradeoff between content material control and worth alignment on the one hand, and the chatbot’s competence to reply open-ended questions on the opposite. To deep seek out out, we queried 4 Chinese chatbots on political questions and compared their responses on Hugging Face - an open-supply platform the place developers can add fashions which can be topic to less censorship-and their Chinese platforms the place CAC censorship applies more strictly. For questions that don't set off censorship, top-rating Chinese LLMs are trailing close behind ChatGPT.
Censorship regulation and implementation in China’s leading models have been effective in proscribing the vary of attainable outputs of the LLMs with out suffocating their capacity to answer open-ended questions. To see the consequences of censorship, we requested each mannequin questions from its uncensored Hugging Face and its CAC-authorised China-based mannequin. A more speculative prediction is that we are going to see a RoPE substitute or at least a variant. Yi, however, was more aligned with Western liberal values (not less than on Hugging Face). Our evaluation indicates that there is a noticeable tradeoff between content material control and worth alignment on the one hand, and the chatbot’s competence to reply open-ended questions on the opposite. To deep seek out out, we queried 4 Chinese chatbots on political questions and compared their responses on Hugging Face - an open-supply platform the place developers can add fashions which can be topic to less censorship-and their Chinese platforms the place CAC censorship applies more strictly. For questions that don't set off censorship, top-rating Chinese LLMs are trailing close behind ChatGPT.
But the stakes for Chinese builders are even higher. A direct observation is that the answers aren't all the time consistent. Like Qianwen, Baichuan’s answers on its official website and Hugging Face sometimes diversified. Watch some videos of the analysis in motion here (official paper site). It’s considerably extra efficient than other models in its class, gets great scores, and the analysis paper has a bunch of details that tells us that DeepSeek has built a crew that deeply understands the infrastructure required to prepare ambitious models. Then he sat down and took out a pad of paper and let his hand sketch strategies for The final Game as he seemed into house, waiting for the family machines to ship him his breakfast and his espresso. 3. Synthesize 600K reasoning data from the internal model, with rejection sampling (i.e. if the generated reasoning had a flawed remaining reply, then it is eliminated).
If you loved this short article and you would certainly like to get even more details concerning ديب سيك kindly browse through the web site.